轻量化视频重建
这个示例展示如何使用一个端到端网络融合两个数据通路重建原始场景
调用接口: - from tianmoucv.proc.reconstruct.TianmoucRecon_tiny
%load_ext autoreload
引入必要的库
%autoreload
import sys,os, math,time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from tianmoucv.data import TianmoucDataReader
import torch.nn.functional as F
import cv2
TianMouCV™ 0.3.5.4, via Y. Lin update new nn for reconstruction
准备数据
train='/data/lyh/tianmoucData/tianmoucReconDataset/train/'
dirlist = os.listdir(train)
traindata = [train + e for e in dirlist]
val='/data/lyh/tianmoucData/tianmoucReconDataset/test/'
vallist = os.listdir(val)
valdata = [val + e for e in vallist]
key_list = []
print('---------------------------------------------------')
for sampleset in traindata:
print('---->',sampleset,'有:',len(os.listdir(sampleset)),'个样本')
for e in os.listdir(sampleset):
print(e)
key_list.append(e)
print('---------------------------------------------------')
for sampleset in valdata:
print('---->',sampleset,'有:',len(os.listdir(sampleset)),'个样本')
for e in os.listdir(sampleset):
print(e)
key_list.append(e)
all_data = valdata + traindata
TinyUNet重建网络调用示例
%autoreload
from tianmoucv.proc.reconstruct import TianmoucRecon_tiny
device = torch.device('cuda:0')
reconstructor = TianmoucRecon_tiny(ckpt_path=None,_optim=False).to(device)#某些版本python和pytorch无法使用_optim
loading..: https://cloud.tsinghua.edu.cn/f/dcbaea7004854939b5ec/?dl=1
load finished
融合图像
%autoreload
from IPython.display import clear_output
from tianmoucv.isp import vizDiff
def images_to_video(frame_list,name,size=(640,320),Flip=True):
fps = 30
ftmax = 1
ftmin = 0
out = cv2.VideoWriter(name,0x7634706d , fps, size)
for ft in frame_list:
ft = (ft-ftmin)/(ftmax-ftmin)
ft[ft>1]=1
ft[ft<0]=0
ft2 = (ft*255).astype(np.uint8)
out.write(ft2)
out.release()
key_list = ['flicker_4']
for key in key_list:
dataset = TianmoucDataReader(all_data,MAXLEN=500,matchkey=key,speedUpRate=1)
dataLoader = torch.utils.data.DataLoader(dataset, batch_size=1,\
num_workers=4, pin_memory=False, drop_last = False)
img_list = []
count = 0
for index,sample in enumerate(dataLoader,0):
if index<0:
continue
if index<= 30:
F0 = sample['F0'][0,...]
F1 = sample['F1'][0,...]
tsdiff = sample['tsdiff'][0,...]
#正向重建
reconstructed_b1 = reconstructor(F0.to(device),tsdiff.to(device), t=-1).float()
inverse_tsdiff = torch.zeros_like(tsdiff)
timelen = tsdiff.shape[1]
for t in range(timelen):
if t < timelen-1:
inverse_tsdiff[0,t,...] = tsdiff[0,timelen-t-1,...] * -1
inverse_tsdiff[1,t,...] = tsdiff[1,timelen-t-1,...]
inverse_tsdiff[2,t,...] = tsdiff[2,timelen-t-1,...]
#逆向重建
reconstructed_b2 = reconstructor(F1.to(device),inverse_tsdiff.to(device), t=-1).float()
#求平均压制TD噪声
reconstructed_b = torch.zeros_like(reconstructed_b1)
for t in range(timelen):
reconstructed_b[t,...] = (reconstructed_b1[t,...]+reconstructed_b2[timelen-t-1])/2
#最后一帧可以扔掉,或者跟下一次的重建的第0帧做个平均,降低一些闪烁感
for t in range(timelen-1):
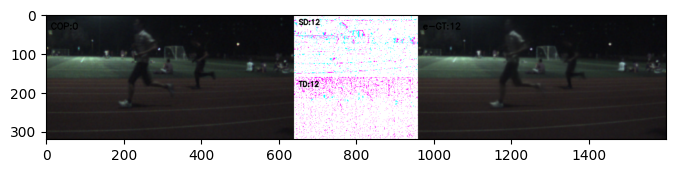
tsd_rgb = tsdiff[:,t,...].cpu().permute(1,2,0)*255
td = tsd_rgb.cpu()[:,:,0]
sd = tsd_rgb.cpu()[:,:,1:]
rgb_sd = vizDiff(sd,thresh=3)
rgb_td = vizDiff(td,thresh=3)
#数据可视化
rgb_cat = torch.cat([rgb_sd,rgb_td],dim=1)
rgb_tsd = F.interpolate(rgb_cat.unsqueeze(0), scale_factor=0.5, mode='bilinear', align_corners=True).squeeze(0).permute(1,2,0)
reconstructed = reconstructed_b[t,...].cpu()
showim = torch.cat([F0,rgb_tsd,reconstructed.permute(1,2,0)],dim=1).numpy()
w = 640
h = 320
# 标注文字
cv2.putText(showim,"e-GT:"+str(t),(int(w*1.5)+12,36),cv2.FONT_HERSHEY_SIMPLEX,0.75,(0,0,0),2)
cv2.putText(showim,"SD:"+str(t),(int(w)+12,24),cv2.FONT_HERSHEY_SIMPLEX,0.6,(0,0,0),2)
cv2.putText(showim,"TD:"+str(t),(int(w)+12,160+24),cv2.FONT_HERSHEY_SIMPLEX,0.6,(0,0,0),2)
cv2.putText(showim,"COP:0",(12,36),cv2.FONT_HERSHEY_SIMPLEX,0.75,(0,0,0),2)
if t==12:
clear_output(wait=True)
plt.figure(figsize=(8,3))
plt.subplot(1,1,1)
plt.imshow(showim)
plt.show()
img_list.append(showim[...,[2,1,0]])
else:
break
images_to_video(img_list,'./viz_'+key+'.mp4',size=(640*2+320,320),Flip=True)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).